









Apple chậm ra mắt Siri tích hợp AI
Tại sự kiện WWDC 2025, Apple xác nhận Siri tích hợp nền tảng trí tuệ nhân tạo Apple Intelligence sẽ được ra mắt vào năm 2026, muộn hơn 1 năm so với kế hoạch ban đầu.


hoặc
Vui lòng nhập thông tin cá nhân
hoặc
Vui lòng nhập thông tin cá nhân
Nhập email của bạn để lấy lại mật khẩu










Một nghiên cứu mới từ Apple cho thấy các mô hình trí tuệ nhân tạo được đánh giá là mạnh nhất hiện nay thực chất vẫn không thể "suy nghĩ", cho thấy mục tiêu chinh phục AGI có thể còn xa hơn dự đoán.
Trong báo cáo khoa học công bố cuối tuần qua mang tên Illusion of Reasoning (Ảo tưởng về tư duy), Apple cảnh báo rằng những mô hình lý luận lớn (Large Reasoning Models – LRM) như OpenAI o1, o3, Claude 3.7 Sonnet Thinking, DeepSeek R1 hay Google Gemini Flash Thinking thực chất chưa thể hiện được khả năng suy nghĩ thực sự. Báo cáo đã gây chú ý mạnh mẽ khi cho rằng con đường tiến tới AGI – trí tuệ nhân tạo tổng quát, với khả năng tư duy và hiểu biết như con người – đang bị đánh giá quá lạc quan.
Nhóm nghiên cứu của Apple không dựa trên những bài kiểm tra tiêu chuẩn vốn có thể bị ảnh hưởng bởi dữ liệu huấn luyện từ Internet, như SAT hay MATH. Thay vào đó, họ xây dựng một môi trường kiểm soát chặt chẽ gồm các bài toán logic cổ điển như Checkers Jumping, River Crossing, Blocks World và đặc biệt là bài toán Tháp Hà Nội.
Mục tiêu là kiểm tra khả năng lý luận thực sự của AI trong những kịch bản không thể "học vẹt", đồng thời có thể theo dõi từng bước suy nghĩ mà mô hình thực hiện – tương tự cách giáo viên theo dõi cách học sinh giải toán để hiểu mức độ hiểu bài.

Kết quả thí nghiệm cho thấy một xu hướng bất ngờ: với các bài toán đơn giản, mô hình AI truyền thống đưa ra lời giải đúng một cách nhất quán, trong khi LRM – vốn được đánh giá có khả năng "suy luận" mạnh – lại có xu hướng thực hiện phức tạp hóa bài toán và đôi khi cho ra kết quả sai. Trong nhóm bài toán ở mức độ trung bình, LRM phát huy sức mạnh khi có thể tạo ra chuỗi suy luận dài và hợp lý, còn các mô hình cũ hơn thì không thể xử lý.
Tuy nhiên, với các bài toán có độ phức tạp cao, cả hai loại mô hình đều bộc lộ điểm yếu rõ rệt – riêng LRM cho thấy độ chính xác càng giảm mạnh khi độ khó tăng, cho đến khi sụp đổ hoàn toàn.
Theo Apple, đây là dấu hiệu cho thấy các mô hình lý luận hiện tại chưa thể suy nghĩ theo cách con người kỳ vọng. Ví dụ, với bài toán Tháp Hà Nội, Claude 3.7 Sonnet Thinking và DeepSeek R1 vẫn xử lý tốt khi số lượng đĩa là 3 hoặc 4, nhưng bắt đầu thất bại hoàn toàn khi thêm đĩa thứ 5 – một bước nhảy không quá lớn về mặt thuật toán nhưng lại khiến mô hình mất khả năng kiểm soát.
Đáng chú ý, Claude 3.7 có thể hoàn thành chính xác hơn 100 bước trong một phiên bản phức tạp của Tháp Hà Nội, nhưng lại thất bại sau bốn bước trong trò chơi River Crossing – vốn đơn giản hơn nhiều.
Nghiên cứu cũng phát hiện một hành vi đáng lo ngại: khi bài toán trở nên quá khó, LRM không những không tăng nỗ lực xử lý mà còn có xu hướng rút ngắn thời gian suy luận. Cụ thể, chúng sử dụng ít token hơn – tức là ít ngôn ngữ suy diễn hơn – trong những câu hỏi khó, điều này trái ngược hoàn toàn với cách tư duy của con người. "Khi tiếp cận một ngưỡng phức tạp nhất định, các mô hình bắt đầu giảm nỗ lực lý luận. Vì vậy, khi vấn đề trở nên rất khó, chúng sẽ sử dụng ít token hơn, tức 'suy nghĩ' ít hơn", nhóm nghiên cứu viết.
Đi sâu vào phân tích, Apple khẳng định không có bằng chứng cho thấy các LRM đang thực hiện các bước suy luận logic một cách hệ thống. Các mô hình chỉ tạo ra những chuỗi văn bản có vẻ hợp lý – thậm chí dài dòng và thuyết phục – nhưng thực chất là sản phẩm của cơ chế dự đoán ngôn ngữ từ dữ liệu huấn luyện. Nói cách khác, chúng không "lý luận", mà chỉ "đoán chữ tiếp theo".
"Những chuỗi suy nghĩ trông có vẻ thông minh, nhưng không có quy trình suy luận thực sự diễn ra. Điều này đặt ra câu hỏi rằng liệu chúng ta có đang phấn khích hay ảo tưởng về khả năng hiện tại của LRM", báo cáo viết.
Nghiên cứu ngay lập tức nhận được phản hồi từ giới chuyên gia. Gary Marcus – học giả nổi tiếng trong lĩnh vực AI và là người thường xuyên cảnh báo về rủi ro công nghệ – nhận định đây là một kết quả "tàn khốc". "Bất kỳ ai nghĩ rằng LLM hoặc LRM là con đường trực tiếp dẫn đến AGI, có thể họ đang tự lừa dối mình", Marcus bình luận trên Substack cá nhân.
Trong khi đó, Andrew Rogoyski, chuyên gia AI của Đại học Surrey (Anh), cho rằng nghiên cứu là lời nhắc rằng ngành công nghiệp AI hiện tại vẫn đang “mò mẫm” trong việc hiểu rõ cách đạt được trí tuệ thực sự. "Phát hiện cho thấy các mô hình hiện nay chỉ có thể xử lý các bài toán dễ đến trung bình. Khi bài toán phức tạp xuất hiện, chúng không còn đủ khả năng phản ứng phù hợp. Điều đó cho thấy chúng ta có thể đã đi đến ngõ cụt với cách tiếp cận hiện nay", ông nói với The Guardian.
Trong bối cảnh các tập đoàn công nghệ đua nhau tuyên bố đột phá về AI, nghiên cứu từ Apple được xem là một hồi chuông cảnh tỉnh quan trọng. Không phủ nhận những tiến bộ vượt bậc trong lĩnh vực AI, nhưng việc thiếu khả năng tư duy logic bền vững và nhất quán cho thấy các hệ thống hiện tại vẫn chưa thể vượt qua ranh giới giữa "giả thông minh" và "thực sự hiểu biết".





Tại sự kiện WWDC 2025, Apple xác nhận Siri tích hợp nền tảng trí tuệ nhân tạo Apple Intelligence sẽ được ra mắt vào năm 2026, muộn hơn 1 năm so với kế hoạch ban đầu.

OpenAI bất ngờ lùi thời điểm ra mắt mô hình AI mã nguồn mở đầu tiên sau nhiều năm. Theo CEO Sam Altman, nhóm nghiên cứu vừa đạt được bước đột phá “rất đáng để chờ đợi”, khiến dự án cần thêm thời gian hoàn thiện.
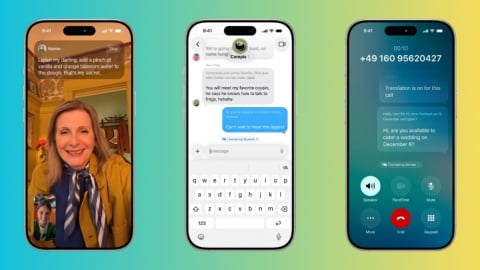
Tính năng Live Translation được tích hợp trong các ứng dụng Messages, FaceTime và Điện thoại, có khả năng dịch trực tiếp theo thời gian thực.

Sự cố dịch vụ diện rộng của Cloudflare ngày 18/11 khiến hàng loạt nền tảng lớn ngưng trệ, cho thấy chỉ một trục trặc từ nhà cung cấp hạ tầng cũng đủ gây hiệu ứng domino trên Internet toàn cầu.

Theo một kế hoạch của Apple đang được đồn đoán, Tim Cook được cho là có thể dừng đảm nhận vị trí CEO vào năm 2026, sau đó ông có thể đảm nhận vai trò Chủ tịch Hội đồng quản trị tập đoàn.

Một sự cố kỹ thuật diện rộng trên hạ tầng đám mây Cloudflare vừa khiến hàng loạt trang web và nền tảng dịch vụ trực tuyến toàn cầu gặp trục trặc.

Trong nửa đầu năm 2025, Meta đã đình chỉ hơn 116.000 tài khoản Facebook và 28.000 tài khoản Instagram tại Việt Nam do liên quan đến gian lận, lừa đảo hoặc các hành vi gây hiểu lầm.

Tài liệu rò rỉ cho biết Microsoft đã nhận hơn 1 tỷ USD tiền chia sẻ doanh thu từ OpenAI sau 6 năm liên tục đầu tư cho công ty khởi nghiệp này.

Trước tình trạng gia tăng quảng cáo, rao bán động vật hoang dã trái phép trên mạng xã hội, Zalo đã triển khai cơ chế quản lý nghiêm ngặt hơn nhằm xây dựng một môi trường trực tuyến an toàn và minh bạch.

Thông tin tại Diễn đàn Đổi mới và Sở hữu trí tuệ lần thứ 6 vừa được tổ chức, Huawei cho biết, công ty đã tạo ra khoảng 630 triệu USD doanh thu từ hoạt động cấp phép bằng sáng chế trong năm 2024.










